本文介绍有监督的机器学习,以及一个基本案例——yolov3-keras图像识别引擎,帮助您快速理解入门机器学习。同时,yolov3其基于python3的特性,也让您很方便的将其进行移植,或者甚至不需要了解太多原理,便可以进行应用了。
1.安装有python3、pip环境的电脑(文章以Ubuntu为例)
2.keras环境及其相关配置
3.tensorflow环境及其相关配置
4.如果需要GPU加速,需要安装Nvidia官方的CUDA工具包以及进行一系列的环境配置(本文省略该步骤,使用的是CPU版本的tensorflow)
首先,简单说说机器学习是什么。这里给出一个机器学习的简单定义,机器学习本质上是根据已经存在的数据,对未来尚未出现的数据做出预测。举个简单的小例子,今天小明午餐吃了米饭,第二天小明午餐还是吃了米饭,这时候自然而然的我们就会猜测,小明第三天中午的午餐依旧是米饭,但是小明明天中午其实依旧是不确定的。
再来讲,我们需要机器学习为我们完成什么样的工作。机器学习可以完成两种工作,即对未来的数据进行预测,以及对结果的判断。前者类似于根据降雨历史进行降水概率的预测,后者类似于在一堆猫和狗的照片里面判断一张照片是猫还是狗狗。
好了,现在我们对机器学习有一个基本的了解了。接下来我们介绍几个基本术语:
1.标签:标签是我们要预测的事物,例如上面说的小明明天的午餐,明天的天气,特定时间的车流量等等。可以简单的认为他就是y=kx+b这个方程里边儿的y值。在真实情况下,y=f(x1,x2,x3,x4....,xn)。
2.特征:特征是输入的变量,可以简单理解成他就是y=kx+b这个方程里边的x值。可以是对小明午餐有影响的一些因素。用一幅图片简单描述一下:

3.样本:样本就是数据的特定实例。就是简单的字面意思,比如历年的降水情况。样本分为有标签的样本和没有标签的样本。以下是随手写的两个样本:

4.损失:损失就是当前预测值和和实际值产生的偏差

机器学习实际上简单的说就是在进行线性回归的操作,就如上面面这幅图,我们假设有一条直线为y=kx+b,这个k和b可以随意取值,我们要做的就是找到最合适的k值和b值,使得我们的直线更能“贴合”已经存在的数据,就是要将损失的和降到最小。而K就是我们所说的权重,x就是上面讲的特征,而y就是标签。而一个机器学习模型做的,就是不断调整权重,使得我们模型的损失降到一个合理的范围。对于我们仅仅应用这个yolov3的视觉识别模型,我们到这里了解的东西已经足够了,如果您希望了解更多机器学习的内容,推荐您参考Google的机器学习公开课,或者其他一系列教材。
这里是keras-yolo3的Github地址(https://github.com/qqwweee/keras-yolo3)
前期环境配置
python3 convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
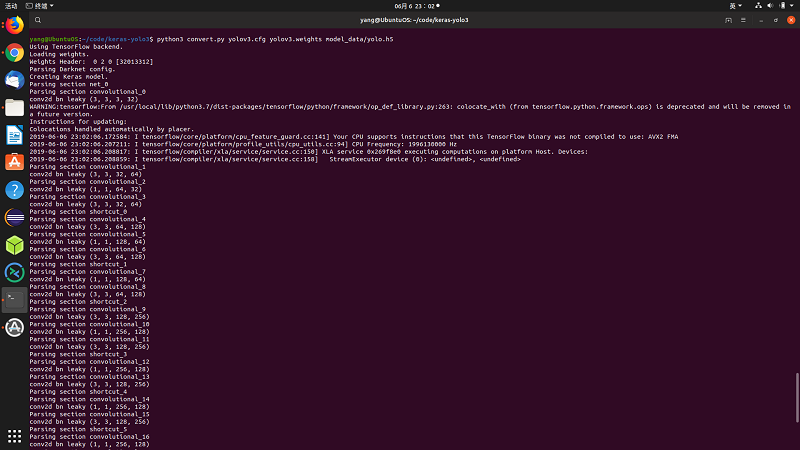
# 使用yolov3.weights生成一个名为yolo.h5的权重文件,存放在model_data文件夹内5.这时候测试一下能否正常使用了,随便拷贝一张照片到你的目录(比如test.jpg):三、训练自己的keras-yolo模型python3 yolo_video.py --image 输入你的文件名就可以得到检测结果了,如下: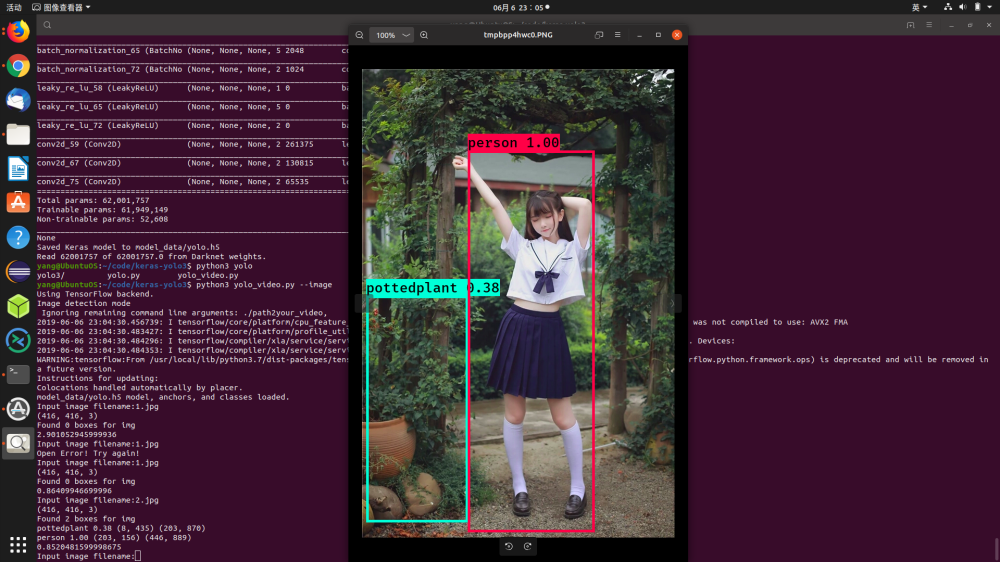
1.创建自己的数据集
这里创建的数据集就是上文提到的样本的集合,这里创建的是有标签的样本,我们需要用图片打标工具把我们需要用到的图片一张一张的打上标签
首先我们要在我们的项目目录下面创建这样一个结构的目录:
VOCdevkit-VOC2007-Annotations ----Layout
-ImageSets---------------Main
-JPEGImages ----Segmentation
-SegmentationClass
-SegmentationObject
-make_main_txt.py
make_main_txt.py中写入如下代码:
import os
import random
trainval_percent = 0.66
train_percent = 0.5
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
其中,JPEGimages文件夹中存放的是你要用的文件(注意只能用.jpg格式的文件),Annotations中存放的是用图片打标工具labelimg(Github地址:https://github.com/tzutalin/labelImg)打标图片后的数据,用法不赘述,如图:


之后运行make_main_txt.py就可在Imageset/main文件夹中生成几个txt文件,这样我们的数据集就制作完成了
运行keras-yolo根目录下的voc_annotation.py:
python3 voc_annotation.py生成三个2007_test.txt、2007_train.txt、2007_val.txt,之后新建一个train1.py文件,复制目录下的train.py的代码到里面。
代码中三个地方比较重要分别是classpath、annotationpath、anchorpath,如图:
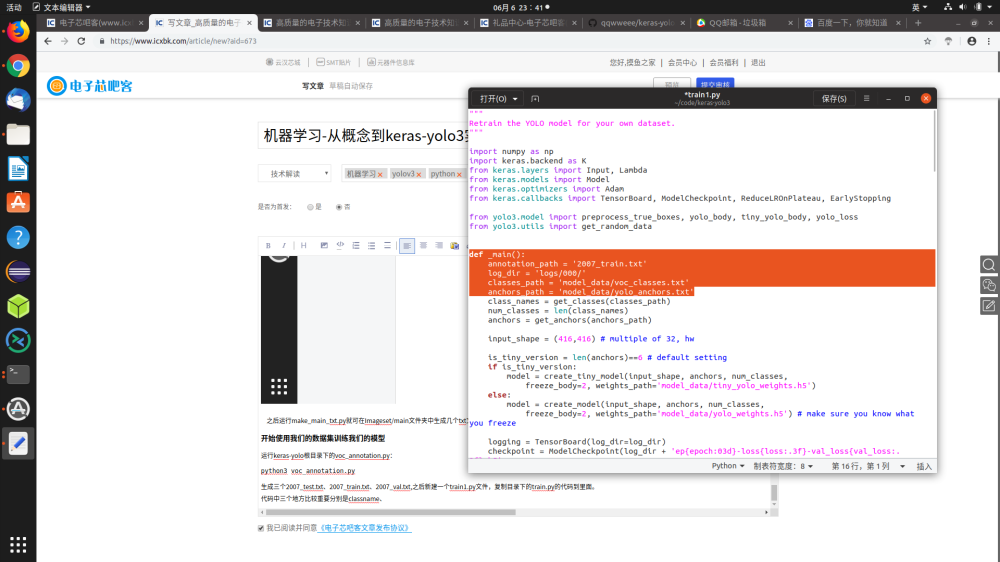
我们将annotationpath改为我们自己的train文件即为“2007_train.txt”,然后将model_data/voc_classes.txt这个文件清空,因为我们这次做的是猫猫的识别,所以我们只填入cat就好,这个classes文件中其实储存的就是我们要用到的标签了,如果像加入多个,每个标签换一行即可,可以看看文件的默认内容就懂了
然后运行train1.py:
python3 train1.py

TIPS:如果遇到程序崩溃等相关问题,那么请修改train1.py文件里边的batch_size默认值为16,性能差的电脑需要调低.最后在logs/000/目录下面就能找到一个h5文件,这就是我们训练好的模型啦。epoch即为迭代,指的是通过训练(即不断调整权重K减少损失的过程),而loss就是我们之前所讲的损失啦,如果你足够有耐心,那么你将看到损失一步步地减小。
原创作品,未经权利人授权禁止转载。详情见转载须知。 举报文章


我要举报该内容理由
×